blockquote style="font-style: italic;">
Feedback for 3. Milestone
MILESTONE PASSED!
Note:
For both tasks: can you please confirm that the development environments, IDE's and packages in the terms of reference (Pflichtenhefte) are the ones actually used. Thank You.
Analysis Server
GENERAL COMMENTS:This project has done very well to craft some code and to create an API that sets a good tone for future work - in a task that was poorly defined by the client and quite explorative in nature. The technologies chosen are state of the art and good programming practices have been selected. The back end does include more logic than can be seen in the tests, and the software engineers have done well to balance functionality and usability within the short time frame given. Quite clearly there are different programmers at work and a Python Programming best practices has not been chosen to guide the development. The tests are very disappointing as I could not get them to work.
Another very pleasing aspect of this work is that there were no exceptions thrown, or long debug output thrown at me while testing the interface. So excellent use of logging and good software design on that front.
On the whole, I am very pleased with the overall quality of what has been produced for this task by students.
TODOs UNTIL 4th MILESTONE:- Standardisation of directory structure, e.g. suggested:
conf
var/res
var/data
var/log
src/ ---> all .py directories and files on the root dir should be moved into here.
tests/ or src/tests --> you decide
- The Terms of Reference (Pflichtenheft), section 3.3, mentions authentication capability which is not implemented. "Autorisierung eines Benutzers bzw. einer Anwendung. // Diese sollte verschluesselt stattfinden."
- Besser Funktionierende Tests - vor allem der Tag Cloud muss etwas verstaendliches (im Kontext der fehlenden, bzw. selbst gewonnenen Testdaten) produzieren. Vgl. Screenshots (Picture 4 / Picture 5).
Some German comments need removing / translation.

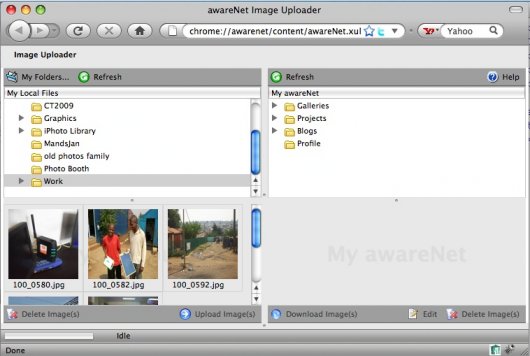
Image Uploader
GENERAL COMMENTS:This is really useful software, and it will change the way people can use awareNet, especially users with little background knowledge. I am very excited to see it in action and it seems that we may get funding from the USA / NSF to try this out in the Grahamstown township, so I am crossing my fingers for this task. The task was much easier than the Analysis Server and well defined, nonetheless, JS / XUL / Firefox programming is very specialised and there must have been a steep learning curve for the programmers. The functionality was very rapidly developed and with an impressive attention to detail including the "online help" button! The structuring of Mozilla projects is excellent so I think that was a good structure into which the work could fit.
I did not see evidence of the project using svn. Can you please confirm this.
Needs more testing - bugs are visible, e.g. uploading a profile picture (screenshot - Picture 5).
I rate this task as excellent.
TODOs UNTIL 4th MILESTONE:- Testing and Bug fixing
- Refresh button should perform a refresh only on the selected folder if possible (still some instability there as explained by Philipp / known issues).
- Authentication aspect as per TOR (Pflichtenheft). Unter 1.1. " Authentifizierung (durch Verwendung von Cookies) ". Unter 1.2 "– Die Anwendung star tet automatisch sobald an den Rechner ein USB-Speichergerat angesteckt wird. " --> I see you will be working on that.
Report to Milestone 3Der 3. Meilenstein war für unser Team der kritischste von allen Meilensteinen, denn in diesem ging es darum, eKhaya für die Analyse-Dienste sowie das Firefox-Plugin lauffähige Funktionalitäten zu präsentieren die alle Aspekte wie z.B. Webservice-Schnittstellen und Datenbanken berücksichtigen.
Und ich kann voller Stolz auf mein Team sagen, dass wir diesen Meilenstein mit all seinen Anforderungen mehr als erfüllen konnten.
zum Firefox PluginBeim Firefox -Plugin sollte zu diesem Meilenstein das Kommunikationsmodul weitesgehend fertiggestellt sein sowie weitere Funktionalitäten über die GUI verwendbar sein.
Hier können wir melden, dass das Pugin nun bis auf den Login und ein paar Kleingikeiten alle Funktionalitäten realisiert.
- Wir können die Favoriten auf die lokalen Verzeichnisse verwalten.
- Wir können lokale Bilder auflisten.
- Wir können ein oder mehrere Bilder per Klick auf den Button oder per Drag & Drop auf den Server hochladen oder vom Server in ein Verzeichnis herunterladen.
- Wir können die Bilder auf dem Server auflisten, editieren und löschen.
- Wir können die Bilder auf dem Server auflisten, editieren und löschen.
- Bilder die gößer als 1024x768px sind werden automatisch verkleinert.
Für den nächsten Meilenstein werden wir noch, die Autostart-Funktion (beim Einstecken eines USB-Geräts) hinzufügen. Ansonsten erfüllen wir soweit alle funktionalen Anforderungen.
Wir benötigen hier noch wie verabredet die endgültige Farbgebung die wir für das Plugin realisieren sollen!
Zu den Analyse-DienstenHier konnten wir nun alle notwendigen Funktionalitäten in einer ersten Version fertigstellen.
Wir können:
- Texte für die lexikalische Analyse speichern.
- Eine Tag-Cloud für eine Liste von UIDs zurückliefern.
- Einen Text mit Label (Klasse) zum Trainieren des Klassifizieres abspeichern.
- Einen Text klassifizieren lassen.
- Das Training des Klassifizierers anstoßen.
All diese Funktionalitäten operieren nun mit einer MySQL-Datenbank und sind über XML-RPC verwendbar.
Aktuell realisieren wir hier folgende XML-RPC-Schnittstellen:
- storeText(UID, title, text)
- getTagCloud(UIDs)
- classify(text, author_id)
- setTrainingData(UID, title, text, author_id, label)
- startTraining()
Folgende Beispielanwendungsfälle können mit diesen Funktionalitäten realisiert werden:
Tag-Cloud für einen oder mehrere Beiträge- Beitrag oder Beiträge mit "store" abspeichern
- Mit UID oder Liste von UIDs der Beiträge die Tagcloud über Aufruf von "getTagcloud" abfragen.
Klassifizierer trainieren- Beiträge mit "setTrainigsData" abspeichern
- Mit "startTraining" Klassifizierer trainieren
Beiträge klassifizieren lassen - Mit "classify" wird der Beitrag übermittelt und das Label bzw. die Klasse zurückgeliefert.
Mir ist gestern im Zuge der Abnahme der Arbeitsergebnisse aufgefallen, dass die Spezifikation die in Zusammenarbeit mit Strix erstellt wurde noch zwei kleine Schwächen hat. Zum einen
soll es bei der Klassifizierung nicht nötig sein die "author_id" mit zu übergeben. Das soll generisch über die Meta-Daten ermöglicht werden. Der andere Punkt betrifft die Methode "store".
Strix hatte sich damals gewünscht, dass diese das Label bzw. die Klasse des abgespeicherten Beitrages als Ergebnis liefert. Das soll wahrscheinlich zum Sinn haben, dass kein "SPAM" in dieTag-Clouds gelangt. Nur kann Strix derzeit mit dem zurückgegebenen Label nichts weiter anfangen. Unsere Leute werden, dass noch mit Strix im laufe der kommenden Woche klären.
Ansonsten lassen sich die RPC-Methoden mit beliebigen XML-RPC Clients (wie sie es auch in PHP gibt) sehr leicht verwenden. Funktional erfüllen wir auch hier soweit alle vereinbarten Funktionalen Anforderungen. Für die kommende Woche werden wir hier die restlichen Fehler beseitigen und das System stabilisieren.
QualitätssicherungFür die kommenden zwei Wochen steht uns nun vor allem die Stabilisierung der Arbeitsergebnisse bevor.
Hierzu gehört:
- Refactoring
- Code-Dokumentation
- Fehlersuche
- Fehlersuche
- Fehlerbehebung
Wir haben hierfür ein separates Team zur Qualitätssicherung bereitgestellt. Dieses Team hat zur Aufgabe für das Firefox-Plugin und die Analyse-Dienste Testläufe zu spezifizieren und auszuführen. Die Arbeitsergbnisse sollen bis zur nächsten Woche diese Testläufe sowie alle Unit-Tests bestehen. Ein formales Dokument über die absolvierten Testläufe wird dann zur abschließenden Dokumentation gehören.